I've long wanted to be able to index and search my own content -- to set up ad hoc "search engines" for different purposes as they come up, with sophisticated search strategies and customized, queryable metadata.
And when I heard about Tantivy, it immediately struck me as a potential vehicle for the search aspirations I'd harbored, as it was reportedly 1) fast, 2) powerful, and 3) written in Rust (all critical components in the Jonathan Strong "potential hobbyist project" rubric).
When it came time to set up the search engine for this site, I knew what I wanted: a Tantivy-based search engine, even if it was a tad bit overkill.
Now, Zola, the (fantastic) static site generator I use, comes with Javascript-based search indexing built in. And, honestly, that's an excellent solution for the vast majority of websites out there.
What I did instead is not the simplest, easiest, or fastest way to integrate site search to a personal site. But it is an opportunity to play with some very cool tech that would be a great choice if you were facing more demanding requirements.
In building a Tantivy-based search engine, we'll learn about:
- Tantivy: its current capabilities, performance, API, and ease of setup
- Zola (static site generator): tweaking its CLI to provide search indexing as a stand-alone task (that optionally uses Tantivy instead of Elasticlunr.js)
- Configuring Tantivy to index Zola's "taxonomies" and other arbitrary metadata
- Setting up a quickie http server in Rust: something to serve the search results to the static pages without too much fuss
Taking Tantivy for a Spin
To begin, we'll start by following Tantivy's tutorial, which takes the library for a spin by indexing and searching Wikipedia using a provided command line interface.
If you don't have Rust installed, you'll need to do that first. I'm using rustc 1.43.0-nightly, but stable is probably fine.
First, clone the tantivy-cli repo and build tantivy, a command-line interface to indexing and searching with the library:
mkdir ~/src/search cd ~/src/search git clone https://github.com/tantivy-search/tantivy-cli.git cd ~/src/search/tantivy-cli cargo build --release cp ~/src/search/tantivy-cli/target/release/tantivy ~/src/search cd ~/src/search ./tantivy --help # Tantivy 0.10.0 # Paul Masurel <paul.masurel@gmail.com> # Tantivy Search Engine's command line interface. # # USAGE: # tantivy <SUBCOMMAND> # # FLAGS: # -h, --help Prints help information # -V, --version Prints version information # # SUBCOMMANDS: # help Prints this message or the help of the given subcommand(s) # index Index files # merge Merge all the segments of an index # new Create a new index. The schema will be populated with a simple example schema # search Search an index. # serve Start a server
Next, download and extract the Wikipedia data (~2.3GB download, 8.3GB uncompressed):
cd ~/src/search wget -O ~/src/search/wiki-articles.json.bz2 https://www.dropbox.com/s/wwnfnu441w1ec9p/wiki-articles.json.bz2?dl=0 bunzip2 ~/src/searchwiki-articles.json.bz2
Building an Index
wiki-articles.json has one JSON object per line with the following structure:
{"body": "some text", "title": "some title", "url": "http://somedomain.com"}
With Tantivy, indexing data requires declaring a schema. The tantivy new subcommand provides an interactive helper utility to do so:
./tantivy new --help # tantivy-new # Create a new index. The schema will be populated with a simple example schema # # USAGE: # tantivy new --index <directory> # # FLAGS: # -h, --help Prints help information # -V, --version Prints version information # # OPTIONS: # -i, --index <directory> Tantivy index directory filepath mkdir wiki-index ./tantivy new --index ./wiki-index # # Creating new index # First define its schema! # # # New field name ? body # Choose Field Type (Text/u64/i64/f64/Date/Facet/Bytes) ? Text # Should the field be stored (Y/N) ? y # Should the field be indexed (Y/N) ? y # Should the term be tokenized? (Y/N) ? y # Should the term frequencies (per doc) be in the index (Y/N) ? y # Should the term positions (per doc) be in the index (Y/N) ? y # Add another field (Y/N) ? y # # # New field name ? title # Choose Field Type (Text/u64/i64/f64/Date/Facet/Bytes) ? Text # Should the field be stored (Y/N) ? y # Should the field be indexed (Y/N) ? y # Should the term be tokenized? (Y/N) ? y # Should the term frequencies (per doc) be in the index (Y/N) ? y # Should the term positions (per doc) be in the index (Y/N) ? y # Add another field (Y/N) ? y # # # New field name ? url # Choose Field Type (Text/u64/i64/f64/Date/Facet/Bytes) ? Text # Should the field be stored (Y/N) ? y # Should the field be indexed (Y/N) ? n # Add another field (Y/N) ? n
The resulting JSON schema file is written to wiki-index/meta.json:
[ { "name": "body", "type": "text", "options": { "indexing": { "record": "position", "tokenizer": "en_stem" }, "stored": true } }, // snip.. ]
Next, index the data (tune --num_threads and --menory_size as desired):
./tantivy index --help # tantivy-index # Index files # # USAGE: # tantivy index [FLAGS] [OPTIONS] --index <directory> # # FLAGS: # -h, --help Prints help information # --nomerge Do not merge segments # -V, --version Prints version information # # OPTIONS: # -f, --file <file> File containing the documents to index. # -i, --index <directory> Tantivy index directory filepath # -m, --memory_size <memory_size> Total memory_size in bytes. It will be split for the different threads. [default: # 1000000000] # -t, --num_threads <num_threads> Number of indexing threads. By default num cores - 1 will be used [default: 3] # note: these values might not make sense on your system! ./tantivy index \ --file wiki-articles.json \ --index ./wiki-index \ --num_threads 16 \ --memory_size 17179869184
With 16 threads and 16GB of ram, indexing finishes in 2 minutes, 46 seconds. The index takes 8.0GB on disk (raw JSON source file is 8.3GB).
Search Performance
Searching with Tantivy is fast.
First, a nearly-instant query with an obscure term with 2 results:
time ./tantivy search -i ./wiki-index -q '"Edgar Luberenga"' | wc -l # 2 # # real 0m0.024s # user 0m0.010s # sys 0m0.013s
Second, a huge query that returns half a million results in less than 30 seconds:
time ./tantivy search -i ./wiki-index -q '"United States"' | wc -l # 447105 # # real 0m28.783s # user 0m27.409s # sys 0m4.443s
For the second example, keep in mind the work done includes pulling (and printing to stdout) all 447,105 articles from disk. The same query, but limited to the top 10 results, runs in about 115ms.
Update: with faster stdout printing (i.e. acquiring lock from std::io::stdout() once instead of simple println!), buffered writing, and avoiding an allocation for JSON serialization, that full retrieval time comes down to 25s. Also, piping to /dev/null instead of wc -l brings the time down further to 18s, suggesting wc -l may be responsible for a significant chunk of the observed time.
A robust benchmark suite comparing Tantivy to Lucene is available here.
The tantivy search output is one raw JSON object per line, which is not ideal for command line exploration. In examples below, I'm using a small python script to pull out specific keys from the JSON.
Phrase queries are supported:
time ./tantivy search -i wiki-index/ -q '"oneohtrix point never"' | ./get-json-key.py title 0 # Kemado Records # Mister Lies # Jon Rafman # Roland SP-404 # Antony and the Johnsons # The Bling Ring # Replica (Oneohtrix Point Never album) # Returnal # Mexican Summer # Chuck Person's Eccojams Vol. 1 # WRPI # Rifts (Oneohtrix Point Never album) # Kveikur # Oneohtrix Point Never # Jefre Cantu-Ledesma # Konx-Om-Pax # Garden of Delete # Instrumental Tourist # # real 0m0.057s # user 0m0.043s # sys 0m0.026s
As is specifying a field:
time ./tantivy search -i wiki-index-v0.12/ -q 'title:ovechkin' | ./get-json-key.py title 0 # Ovechkin # Alexander Ovechkin # Andrei Ovechkin # Artem Ovechkin # Valentin Ovechkin # # real 0m0.044s # user 0m0.044s # sys 0m0.016s
Elasticlunr.js Attempts Wikipedia
Now, if you remember, we're supposed to be building a site search server out of this. But out of curiosity, I wanted to see how the Javascript-based search engine did on the Wikipedia dataset.
Zola's built-in search is based on the Elasticlunr.js library, which describes itself as "a lightweight full-text search engine developed in JavaScript for browser search and offline search" that is "a bit like Solr, but much smaller and not as bright, but also provide flexible configuration, query-time boosting, field search and other features."
There's also a Rust crate, elasticlunr-rs, which is "intended to be used for generating compatible search indices."
I decided to write a small indexing script in Rust (as opposed to native Javascript) for two reaons:
- I had a premonition the indexing would be slow in Javascript
- After five minutes scanning the Elasticlunr.js docs I didn't see anything about saving the index to file
After groking the elasticlunr-rs docs, I realize the Rust crate has the same issue as the Javascript library: the only interface to the serialized index output for saving to file is the Index::to_json method, which returns a String.
What concerns me is that at the moment that the serialized JSON string is returned from Index::to_json, the index itself will be in memory as well as the entirety of its serialized form. I happen to have plenty of RAM but it doesn't seem like a robust design for potentially large corpora.
In any event, here are the CliffsNotes of the Rust program I wrote to index Wikipedia with elasticlunr-rs (full code here):
#[derive(Deserialize, Debug)] struct Record { pub title: String, pub body: String, pub url: String, } fn main() -> Result<(), io::Error> { // snip.. let mut index = elasticlunr::Index::new(&["title", "body"]); // snip.. while let Some(line_result) = lines.next() { let line: &[u8] = line_result?; let rec: Record = serde_json::from_slice(line) .map_err(|e| { io::Error::new( io::ErrorKind::InvalidData, format!("deserializing failed: {}", e) ) })?; index.add_doc(&rec.url, &[&rec.title, &rec.body]); } // snip.. // hope you have plenty of ram! let index_json: String = index.to_json(); wtr.write_all(index_json.as_bytes())?; // snip.. }
An hour later, the program is still running. Ram is at 24G and that's before we call .to_json() and hope for the best.
Some hours later, the system (128GB of ram) runs out of memory:
09:17 PM jstrong@coolidge:~/src/search/js$ ./target/release/indexer
memory allocation of 34359738368 bytes failedAborted (core dumped)
12:19 AM jstrong@coolidge:~/src/search/js$
Hmm. Guess our analysis will have to wait.
We Now Return to our Regularly Scheduled Program
tantivy actually comes with a built-in web server that handles phrase queries and field searching out of the box:
./tantivy serve -i ./wiki-index --host 127.0.0.1 --port 6789 # in another shell ... curl http://127.0.0.1:6789/api/?q=title:%22tiger%20muskellunge%22 { "q": "title:\"tiger muskellunge\"", "num_hits": 1, "hits": [ { "score": 25.37431, "doc": { "body": [ "\nTiger muskellunge\n\nThe tiger muskellunge (\"Esox masquinongy × lucius\" or \"Esox lucius × masquinongy\"), commonly called tiger muskie, is a carnivorous fish, and is the usually-sterile, hybrid offspring of the true muskellunge (\"Esox masquinongy\") and the northern pike (\"Esox lucius\"). <snip..>" ], "title": [ "Tiger muskellunge" ], "url": [ "https://en.wikipedia.org/wiki?curid=446448" ] }, "id": 375293 } ], "timings": { "timings": [ { "name": "search", "duration": 339, "depth": 0 }, { "name": "fetching docs", "duration": 158, "depth": 0 } ] } }
For now, tantivy serve will work a search server, which leaves indexing site content as our biggest remaining obstacle.
It seems to me that the easiest place to put new search indexing functionality of Zola content files is inside Zola's CLI itself, since that code will have ready access to code for handling various time-consuming tasks like parsing the content directory, stripping html, etc.
Since it's possible that adding this functionality may be of use to someone else, it would be nice to extend the existing Zola CLI in a broadly usable way and, depending on interest, submit the changes as a pull request to Zola. So, I fork Zola and begin hacking on it.
CLI Engineering
Zola's search indexing code is primarily in components/search/src/lib.rs, while the command line options are defined in src/cli.rs.
First, I add a new subcommand, zola index, that will perform indexing as a stand-alone task that can be integrated with our build pipeline:
// in src/cli.rs // snip.. SubCommand::with_name("index") .about("Create a search index as a stand-alone task, and with additional options") .args(&[ Arg::with_name("index_type") .long("index-type") .short("t") .takes_value(true) .possible_values(&["elasticlunr", "tantivy"]) .required(true) .help("what kind of search index to build"), Arg::with_name("output_dir") .short("o") .long("output-dir") .default_value("public") .takes_value(true) .help("Outputs the generated search index files into the provided dir. \ Note: Tantivy indexing produces a directory instead of a file, \ which will be located at output-dir/tantivy-index"), Arg::with_name("drafts") .long("drafts") .takes_value(false) .help("Include drafts when loading the site"), ]), // snip..
The resulting --help looks like this:
./target/release/zola index --help # zola-index # Create a search index as a stand-alone task, and with additional options # # USAGE: # zola index [FLAGS] [OPTIONS] --index-type <index_type> # # FLAGS: # --drafts Include drafts when loading the site # -h, --help Prints help information # -V, --version Prints version information # # OPTIONS: # -t, --index-type <index_type> what kind of search index to build [possible values: elasticlunr, tantivy] # -o, --output-dir <output_dir> Outputs the generated search index files into the provided dir. Note: Tantivy # indexing produces a directory instead of a file, which will be located at output- # dir/tantivy-index [default: public]
Initially, I just want to get the new command to use the existing indexing code correctly. Although there's a good bit of "bookkeeping" like handling the new subcommand, adding a submod where the command code goes, etc., the guts of it is really in Site::build.
The Site struct (full file) holds loaded files and configuration for the site that's being rendered:
// in components/site/src/lib.rs impl Site { // snip.. /// Deletes the `public` directory and builds the site pub fn build(&self) -> Result<()> { self.clean()?; // Generate/move all assets before rendering any content if let Some(ref theme) = self.config.theme { let theme_path = self.base_path.join("themes").join(theme); if theme_path.join("sass").exists() { self.compile_sass(&theme_path)?; } } if self.config.compile_sass { self.compile_sass(&self.base_path)?; } if self.config.build_search_index { self.build_search_index()?; // <- here's what we came for } // snip... (search indexing can't depend on what comes after) }
In the build_search_index method that is called, the code just loops through the available sections and pages that make up the site, removes all HTML/CSS/JS code, and feeds the remaining text to an elasticlunr::Index. Although the Sass compilation does take place in build prior to search indexing, it seems very unlikely that producing CSS assets would impact search indexing.
When finished, as a heuristic to check the results, I run zola build with search indexing, as well as my new command, and compare the resulting indexes:
fd --extension js 'index' ./public --exec md5sum # 8f1a9d115462075d7d17dfea6ef6e4ca public/build-index.js # 8f1a9d115462075d7d17dfea6ef6e4ca public/new-index-index.js
Diff of this initial step here.
Next step is adding Tantivy as an optional dependency, and using conditional compilation to skip the zola index subcommand unless #[cfg(feature = "tantivy")] is enabled.
Zola is organized as a collection of workspaces, which can sometimes be confusing to get right in terms of conditional compilation. I had to declare Tantivy as an optional dependency both in zola/Cargo.toml and zola/search/Cargo.toml:
# in zola/Cargo.toml AND zola/search/Cargo.toml: tantivy = { version = "0.12", optional = true }
Then I could base the CLI menu based on whether the feature was present:
// in zola/src/cli.rs // snip.. SubCommand::with_name("index") .about("Create a search index as a stand-alone task, and with additional options") .args({ // bracket creates new block let drafts = Arg::with_name("drafts") .long("drafts") .takes_value(false) .help("Include drafts when loading the site"); #[cfg(feature = "tantivy")] // only compiled if --features tantivy { let index_type = Arg::with_name("index_type") .long("index-type") .short("t") .takes_value(true) .possible_values(&["elasticlunr", "tantivy"]) .required(true) .help("what kind of search index to build"); let output_dir = Arg::with_name("output_dir") .short("o") .long("output-dir") .default_value("public") .takes_value(true) .help("Outputs the generated search index files into the provided dir. \ Note: Tantivy indexing produces a directory instead of a file, \ which will be located at output-dir/tantivy-index"); &[drafts, index_type, output_dir] } #[cfg(not(feature = "tantivy"))] // compiled when not --features tantivy { &[drafts] } }), // snip..
With those changes in place, we can now compile Zola either with support for Tantivy ...
cargo build --bin zola --features tantivy ./target/debug/zola index --help zola-index Create a search index as a stand-alone task, and with additional options USAGE: zola index [FLAGS] [OPTIONS] --index-type <index_type> FLAGS: --drafts Include drafts when loading the site -h, --help Prints help information -V, --version Prints version information OPTIONS: -t, --index-type <index_type> what kind of search index to build [possible values: elasticlunr, tantivy] -o, --output-dir <output_dir> Outputs the generated search index files into the provided dir. Note: Tantivy indexing produces a directory instead of a file, which will be located at output- dir/tantivy-index [default: public]
... or without:
cargo build --bin zola ./target/debug/zola index --help zola-index Create a search index as a stand-alone task, and with additional options USAGE: zola index [FLAGS] FLAGS: --drafts Include drafts when loading the site -h, --help Prints help information -V, --version Prints version information
The Hard Part
With everything in place, it's time to implement the indexing code with Tantivy. It turned out to be more difficult than what I had in my imagination.
First hurdle: Zola is fastidious about language configuration, and its existing search indexing is language-aware. But following suit in our new index subcommand creates an inconvenience because Zola's configuration files encode language using a two-character ISO code (e.g. "en", "fr", "de"), while Tantivy's native Language enum offers only bare-bones deserialization (basically, it can handle full, capitalized language names e.g. "English", "French", "German").
I end up bringing in a new crate, isolang, because coding up an ISO-639-1 lookup table sounds a pain.
But, there's several complications even after adding the new dependency:
- There are two-character language codes and three character language codes, each with their own ISO specifications, so I write code to handle both cases. I also decide to add a fallback to handle if the (capitalized) language name is passed
- Tantivy's
Languageenum implementsserde::Serializeandserde::Deserialize, and I can useisolangto parse the ISO code and get a string name (e.g. "German"). But simply deserializing the string "German" as aLanguagedoes not seem to work, so I end up needing to create a temporary struct with alanguageattribute and encoding a JSON object just to parse the language name string - Also, I have to keep both the original ISO code
&strrepresentation, and the parsedLanguage, in scope throughout the indexing function because both are needed depending on the situation, which is confusing to follow
All in all, it's not the end of the world, but is quite a lot of grief for what seems like very simple functionality: parsing the language name.
This is the ugly parsing function I ended up with:
#[cfg(feature = "tantivy-indexing")] fn parse_language(lang: &str) -> Option<tantivy::tokenizer::Language> { use serde_derive::Deserialize; #[derive(Deserialize)] struct Lang { pub language: tantivy::tokenizer::Language, } // expecting two-character code, but will try other forms as fallback match lang.len() { 2 => isolang::Language::from_639_1(&lang.to_lowercase()) .and_then(|parsed| { let json = format!("{{\"language\":\"{}\"}}", parsed.to_name()); serde_json::from_str::<Lang>(&json).ok().map(|Lang { language }| language) }), 3 => isolang::Language::from_639_3(&lang.to_lowercase()) .and_then(|parsed| { serde_json::from_str::<tantivy::tokenizer::Language>(parsed.to_name()).ok() }), // apparently not a code, so cross your fingers and hope for the best _ => serde_json::from_str::<tantivy::tokenizer::Language>(&format!("{{\"language\":\"{}\"}}", lang)).ok() } }
When I finally get into the weeds of Tantivy's API, I find there are a lot of concepts to understand, a problem that is exacerbated by the relatively busy interfaces. What I mean by "busy" is, there seems to be several ways to do the same thing, and sometimes it's confusing whether something is required, or provided for convenience, or just OBE and hasn't been deleted yet.
Case-in-point: Tantivy's IndexWriter, which is the handle for adding documents to an Index, offers a IndexWriter::commit method to call after having updated an Index, after which the changes are guaranteed to be on disk:

But there is also IndexWriter::prepare_commit:
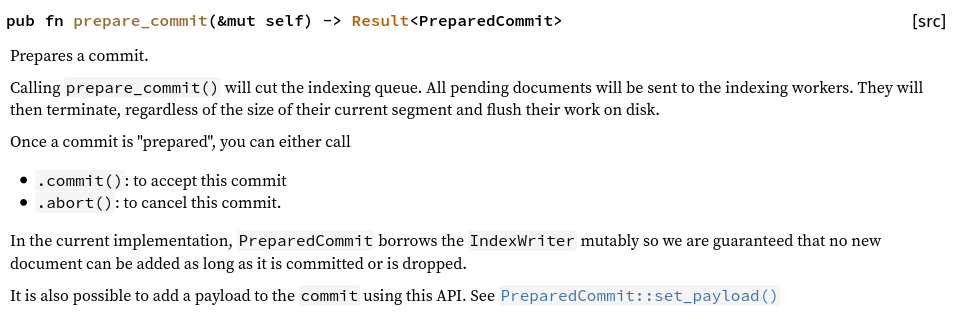
It isn't clear how prepare_commit relates to commit: is it required to be called, may be called, should be called, or should not be called prior to calling commit?
Now, let me pause to note a few things:
- Most of the complexity stems from the powerful functionality that Tantivy provides, not from bad API design
- Based on a tiny amount of experience, modest amount of research, and very generous disdain for all things Java, Lucene and Solr seem about 100x worse to me
- Tantivy is pre-v1.0 (v0.12), it's still a young project and I'm sure the API will be enhanced along the way
After some more hacking my first pass at Tantivy-based indexing of Zola site content is complete:
#[cfg(feature = "tantivy-indexing")] pub fn build_tantivy_index( lang: &str, library: &Library, output_dir: &str, ) -> Result<()> { use tantivy::{schema::*, tokenizer::*, Index, Document}; use tantivy::doc; let parsed_lang: Language = parse_language(lang) .ok_or_else(|| { Error::from(format!("failed to parse language: '{}'", lang)) })?; let tokenizer_name: String = match parsed_lang { Language::English => "en_stem".to_string(), other => format!("{:?}_stem", parsed_lang).to_lowercase(), }; let mut text_indexing_options = TextFieldIndexing::default() .set_index_option(IndexRecordOption::WithFreqsAndPositions) .set_tokenizer(&tokenizer_name); let text_options = TextOptions::default() .set_indexing_options(text_indexing_options) .set_stored(); let mut schema_bldr = SchemaBuilder::new(); let title = schema_bldr.add_text_field("title", text_options.clone()); let body = schema_bldr.add_text_field("body", text_options.clone()); let permalink = schema_bldr.add_text_field("permalink", STORED); let schema = schema_bldr.build(); let index_dir = std::path::Path::new(output_dir).join("tantivy-index"); let mut index = Index::create_in_dir(&index_dir, schema.clone()) .map_err(|e| { Error::from(format!("creating tantivy index failed: {}", e)) })?; if index.tokenizers().get(&tokenizer_name).is_none() { // if non-english, we need to register stemmer let tokenizer = TextAnalyzer::from(SimpleTokenizer) .filter(RemoveLongFilter::limit(40)) .filter(LowerCaser) .filter(Stemmer::new(parsed_lang)); index.tokenizers().register(&tokenizer_name, tokenizer); } let mut wtr = index.writer(1024 * 1024 * 256) .map_err(|e| { Error::from(format!("creating tantivy index writer failed: {}", e)) })?; let mut seen: HashSet<String> = Default::default(); let mut n_indexed = 0; for section in library.sections_values() { if section.lang != lang { continue } if ! section.meta.in_search_index { continue } for key in §ion.pages { let page = library.get_page_by_key(*key); if !page.meta.in_search_index { continue } if seen.contains(&page.permalink) { continue } seen.insert(page.permalink.clone()); // remove markup code let cleaned_body: String = AMMONIA.clean(&page.content).to_string(); let opstamp = wtr.add_document(doc!( title => page.meta.title.as_ref().map(|x| x.as_str()).unwrap_or(""), body => cleaned_body.as_str(), permalink => page.permalink.as_str(), )); println!("added {:?} {}", opstamp, page.permalink); n_indexed += 1; } } wtr.prepare_commit().map_err(|e| { Error::from(format!("tantivy IndexWriter::commit failed: {}", e)) })?; let commit_opstamp = wtr.commit().map_err(|e| { Error::from(format!("tantivy IndexWriter::commit failed: {}", e)) })?; wtr.wait_merging_threads().map_err(|e| { Error::from(format!("tantivy IndexWriter::wait_merging_threads failed: {}", e)) })?; drop(index); println!("finished indexing {} pages", n_indexed); Ok(()) }
Tantivy's API: A Primer
A quick primer on some of the concepts at play in the indexing code above:
- An
Indexis a search index, possibly in memory, possibly on disk. It has aSchema, which is similar to a database table schema, with named, typed fields. - Each
Fieldin theSchema(Fieldis just ani32wrapper that represents the internal id number of a field) permits a wide degree of settings regarding how its content is tokenized. As the Tantivy docs day, "Tokenizer are in charge of chopping text into a stream of tokens ready for indexing." - The full text of a
Fieldmay also be stored in theIndex, or not - A given tokenizer is
- declared by name in a
Field's configuration, - added (embedded in the
Field) to aSchema, and, - after the
Schemais used to create anIndex, the tokenizer (aTextOptionsinstance) must be registered on theIndex'sTokenizerManagerwith a name that matches the name used in theFieldadded to theSchemaearlier
- declared by name in a
- A handle to write to the
Indexcomes in the form of anIndexWriter, which utilizes a multithreaded implementation behind the scenes - Content is added to the
Index(via anIndexWriter) in the form of aDocument, essentially a map of field name to data - An
Indexis processed in pieces calledSegments (I'm not sure how closely aSegmentcorresponds to one of theIndex's files on disk, but my impression is fairly closely) - A
Searcherexecutes searching logic onSegments (via anIndexReader, the read corollary to anIndexWriter) - A
Collectorprocesses the results of theSearcher, for instance gathering only the top 10 results, or only a count of the results
After some typical debugging for syntax errors and the like, I finally produce an index. Excitedly, I race to search it for the first time, only to find an end of buffer while reading a VInt error (I hate those):
../zola-fork/target/debug/zola index -t tantivy -o public --drafts Building search index... Done in 2.8s. ../search/tantivy search -i public/tantivy-index/ -q test IOError(IOError { path: None, err: Custom { kind: InvalidData, error: "Reach end of buffer while reading VInt" } })
Flummoxed, I give up and go to bed. The next day, it hits me like a ton of bricks: incompatible Tantivy versions!
tantivy (from tantivy-cli repo) used v0.10, while I had used v0.12 in my Zola indexer. This is, ideally, something you'd want Tantivy to catch and warn about, but it appears they're already on the case.
It takes a bit of hacking to bring the v0.10 based tantivy code up to v0.12 Tantivy, but pretty soon I'm in business:
../search/tantivy search -i public/tantivy-index -q tantivy | ../search/get-json-key.py title 0 # Building Site Search With Tantivy
Excellent! Almost there!
Integrating Tantivy Results With jstrong.dev
After cleaning up the Zola indexing code a bit, it's time to bring Tantivy results to the jstrong.dev search box:

Womp womp: jstrong.dev search before "Building Site Search With Tantivy"
Three #!@&-ing hours of Javascript later...
I failed to configure any of the several autocomplete libraries I tried. There's nothing worse than fiddling with Javascript for hours -- what a mess! Maybe I'll pay an expert next time, or something.
I end up doing something extremely hacky to get some results up, which is to just make the form method GET, pointing to /search, and on that page grab the query string in Javascript, triggering an AJAX call that will populates the results.
The empty html waiting for search results:
<section class='search-results article-list'> <h1 id="search-headline" class="article-headline"> Search Results </h1> <ul class="list-group pl-md-2 ml-md-5 mt-5" id="search-items" ></ul> </section>
The Javascript to populate the results, which runs when the page loads:
function get(url, callback) { var xhr = new XMLHttpRequest(); xhr.open('GET', url); xhr.onload = function() { if (xhr.status === 200) { callback(JSON.parse(xhr.responseText)); } else { console.log('Request failed. Returned status of ' + xhr.status); } }; xhr.send(); } var urlParams = new URLSearchParams(window.location.search); var q = urlParams.get('q'); document.getElementById('search-headline').innerHtml = `Search Results: '${q}'`; document.getElementById('nav-search-input').value = q; var searchHost = '<server that can search stuff>'; get(`${searchHost}/api?q=${encodeURI(q)}`, function(resp) { resp.hits.forEach(function(x) { var url = x.doc.permalink[0]; var title = x.doc.title[0]; $('<li />') .addClass('list-group-item search-result ml-sm-0') .attr('style', 'border-top:0; border-left: 0; border-right: 0') .html(` <table class="table table-borderless w-auto"> <tbody> <tr> <td><p class="text-nowrap"></p></td> <td> <p class="text-left"> <a class="search-result-item" href="${x.doc.permalink[0]}">${x.doc.title[0]}</a> </p> </td> </tr> </tbody> </table> `).appendTo('ul#search-items'); }); })
Whatever, I'll improve it later.
Souping Up the Search Results
One of the things that inspired me to start on this was Zola's "taxonomies," which are arbitrary metadata categories you can assign to pages.
In Zola, content is in Markdown, but each file has a special, TOML-encoded "front matter" section at the top (enclosed by '+++' separators). Taxonomies are part of the front matter schema and are used to organize the site's content at render time.
Out of the gate, I started encoding elaborate metadata in my pages, which amused me perhaps more than it should have. For example, the taxonomies section for this article:
[taxonomies] tldr = [ """Tantivy is a blazing fast search engine library in Rust with a modern design and powerful features on par with Lucene""", """In this article, I'll be creating a custom search engine for jstrong.dev that uses Tantivy under the hood""", """Major steps include integrating Tantivy-based indexing into a static site generator (Zola), adding page metadata to the search index schema, and standing up a small http server to process queries""", ] breadcrumbs = ["posts", "tantivy site search"] keywords = [ "search", "search engine", "full text search", "tantivy", "lucene", "elasticsearch", "solr", "elasitclunr", "site search", "Paul Masurel", "Vincent Prouillet", "zola", "static site generator", "hugo", "jekyll", "rust", "ajax", "autocomplete", ] programming-languages = ["rust", "javascript", "css", "html", "java"] programming-libraries = [ "tantivy", "zola", "lucene", "solr", "elasticlunr", "bootstrap", "jquery", "iron", ] people = ["Paul Masurel", "Vincent Prouillet"] animal-mascots = ["Tantivy: cheesy logo with a horse"] sections = ["posts"] tags = ["search", "jstrong.dev internals", "javascript: fiddling and twiddling"]
Now that I've got basic search indexing, I want to be add the ability to search by any of these categories. I want to be able to search programming-language:python slow. I want to search person:"Vincent Prouillet" when I'm feeling grateful I'll never have to touch the Hugo templating language ever again. And I even want to search mountain:"grand teton" to find articles about my youthful adventures if I feel like it!
So lets make it happen.
Taxonomies: Indexed
Taking indexing to the next level is not that bad.
Generally, I need to keep track of a few additional things while looping through the pages, and add documents to the index at the very end. For instance, I keep a HashSet<String> of every unique taxonomy name encountered so I when I define the schema, each can be added as a Field:
// in body of build_tantivy_index (zola/components/search/src/lib.rs) struct IndexContent<'a> { pub title: &'a str, pub description: &'a str, pub permalink: &'a str, pub body: String, // page-only (not present in sections) pub datetime: Option<DateTime<Utc>>, pub taxonomies: &'a HashMap<String, Vec<String>>, } let mut seen: HashSet<String> = Default::default(); // unique permalinks already indexed (don't index same page twice) let mut all_taxonomies: HashSet<String> = Default::default(); // remember any taxonomy used anywhere so we can add to schema let mut index_pages: Vec<IndexContent> = Vec::new(); // keep the content so we can add it to the index later let mut n_indexed = 0; let empty_taxonomies: HashMap<String, Vec<String>> = Default::default(); for section in library.sections_values() { // reason for macro: Section/Page are different types but have same attributes. // yes, that's what traits are for, but that would take longer macro_rules! extract_content { ($page:ident) => {{ let already_indexed = seen.contains(&$page.permalink); if ! already_indexed && $page.meta.in_search_index && $page.lang == lang { seen.insert($page.permalink.clone()); // mark ask indexed n_indexed += 1; let cleaned_body: String = AMMONIA.clean(&$page.content).to_string(); Some(IndexContent { title: $page.meta.title.as_ref().map(|x| x.as_str()).unwrap_or(""), description: $page.meta.description.as_ref().map(|x| x.as_str()).unwrap_or(""), permalink: $page.permalink.as_str(), body: cleaned_body, // page-only fields, leave blank datetime: None, taxonomies: &empty_taxonomies, }) } else { None } }} } if section.meta.redirect_to.is_none() { if let Some(content) = extract_content!(section) { index_pages.push(content); } } for key in §ion.pages { let page = library.get_page_by_key(*key); match extract_content!(page) { Some(mut index_content) => { all_taxonomies.extend(page.meta.taxonomies.keys().map(|x| x.to_string())); index_content.taxonomies = &page.meta.taxonomies; index_content.datetime = parse_dt_assume_utc(&page.meta.date, &page.meta.datetime); index_pages.push(index_content); } None => {} } } }
With that in place, actually adding to the index is pretty easy:
// in body of build_tantivy_index (zola/components/search/src/lib.rs) let mut schema = SchemaBuilder::new(); let mut fields: HashMap<String, Field> = Default::default(); for text_field_name in &["title", "body", "description"] { fields.insert(text_field_name.to_string(), schema.add_text_field(text_field_name, text_options.clone())); } fields.insert("permalink".to_string(), schema.add_text_field("permalink", STORED)); fields.insert("datetime".to_string(), schema.add_date_field("datetime", STORED | INDEXED)); let reserved_field_names: HashSet<String> = fields.keys().map(|s| s.to_string()).collect(); for taxonomy_name in all_taxonomies.difference(&reserved_field_names) { fields.insert(taxonomy_name.to_string(), schema.add_text_field(taxonomy_name.as_str(), text_options.clone())); } // snip.. for page in index_pages { let mut document: Document = doc!( fields["title"] => page.title, fields["description"] => page.description, fields["permalink"] => page.permalink, fields["body"] => page.body, ); if let Some(utc) = page.datetime { document.add_date(fields["datetime"], &utc); } for (taxonomy, terms) in page.taxonomies.iter().filter(|(k, _)| ! reserved_field_names.contains(k.as_str())) { for term in terms.iter() { document.add_text(fields[taxonomy], term); } } wtr.add_document(document); }
I build it and check:
../search/tantivy search -q 'mountains:"grand teton"' -i dist/search/tantivy-index/ | ../search/get-json-key.py title 0 Unsafe At Any Altitude
It works!
Ok, can I search by "animal-mascots"?
../search/tantivy search -q 'animal-mascots:cheesy' -i dist/search/tantivy-index/ | ../search/get-json-key.py title 0 InvalidArgument("Query is invalid. SyntaxError")
Drat. Turns out hyphens aren't allowed. The regex for name permissibility is in Tantivy's source code and I double-check: no, no hyphens allowed:
echo 'animal-mascots' | rg '^[a-zA-Z][_a-zA-Z0-9]*$' echo $? # 1
That's OK, we'll swap in underscores for indexing and deal with it on the query parsing end:
#[cfg(feature = "tantivy-indexing")] fn normalize_taxonomy_name(s: &str) -> String { s.replace("-", "_") }
../search/tantivy search -q 'animal_mascots:cheesy' -i dist/search/tantivy-index/ | ../search/get-json-key.py title 0 Building Site Search With Tantivy ../search/tantivy search -q 'programming_languages:python body:slow' -i dist/search/tantivy-index/ | ../search/get-json-key.py title 0 Building Site Search With Tantivy
Now we're in business!
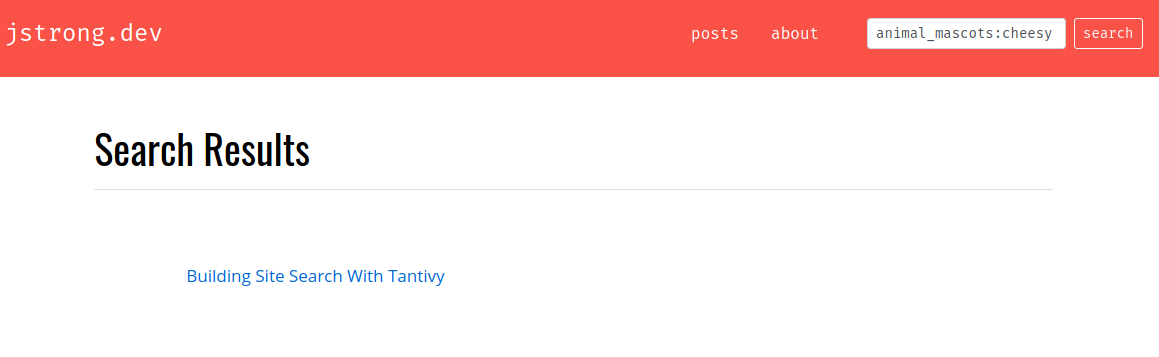
With an incredibly powerful search engine integrated into jstrong.dev, I now have the ability to make silly gags
Roadmap
Another issue I haven't figured out is how I'm going to deal with singular/plural issues: the taxonomy names are plural, but it feels better to search for the singular term. For example: taxonomy name is "people", but it'd be nice to search for "person:Steve Jobs", instead of "people:Steve Jobs". Steve Jobs isn't a people.
I'll also need to tweak the search results to weight fields differently. From what I saw it seemed like boosting the importance of a given field isn't too hard, but I'm not sure about boosting the importance of a result based on the document's value for a given field. Ideally the results would boost more recent items over older articles.
When that's in place, I will have to take a deep breath, brace myself, and descend into the dark world of Javascript/HTML/CSS once more to make the search results UI somewhat decent.
I'll probably also want to publish some more articles so this search engine is at least somewhat useful!